3.10. Building a Regression Tree#
The purpose of a regression tree is to predict a number for a given pieces of input data. Let’s consider a scenario where we want to predict ice cream daily sales of an ice cream truck based on the weather.
Consider the following training data:
Temperature (Celsius) |
Rain |
Sales ($) |
|---|---|---|
22 |
0 |
3700 |
-2 |
0 |
50 |
31 |
0 |
6200 |
18 |
1 |
900 |
16 |
0 |
1300 |
24 |
1 |
3100 |
22 |
1 |
2500 |
28 |
0 |
5100 |
18 |
0 |
4200 |
21 |
0 |
2800 |
26 |
0 |
4100 |
29 |
1 |
5400 |
For the rain variable, 0 means no rain and 1 means there was rain.

Building a regression tree is quite similar to building a classification tree. We tend to try to sort the training samples based on their output variable, in this case, it’s the daily sales.
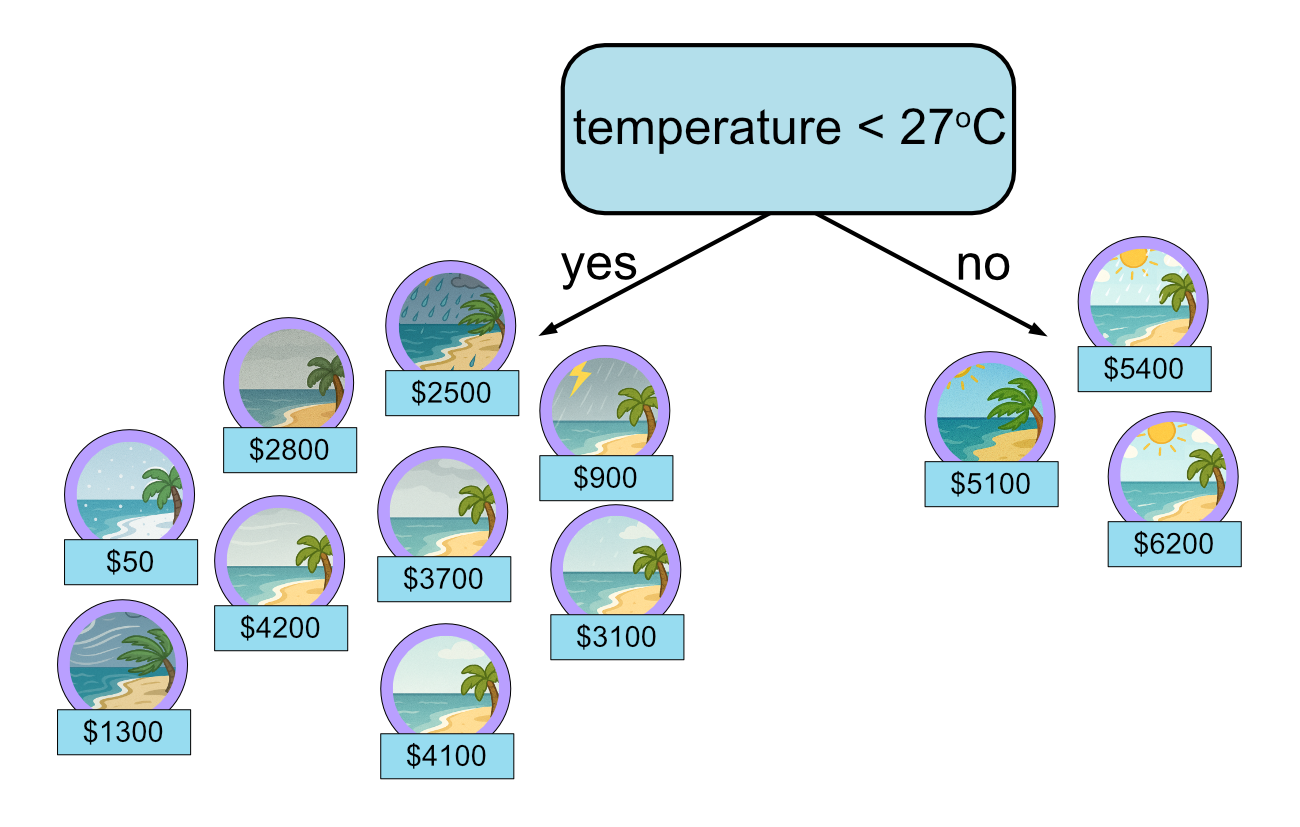
First decision.
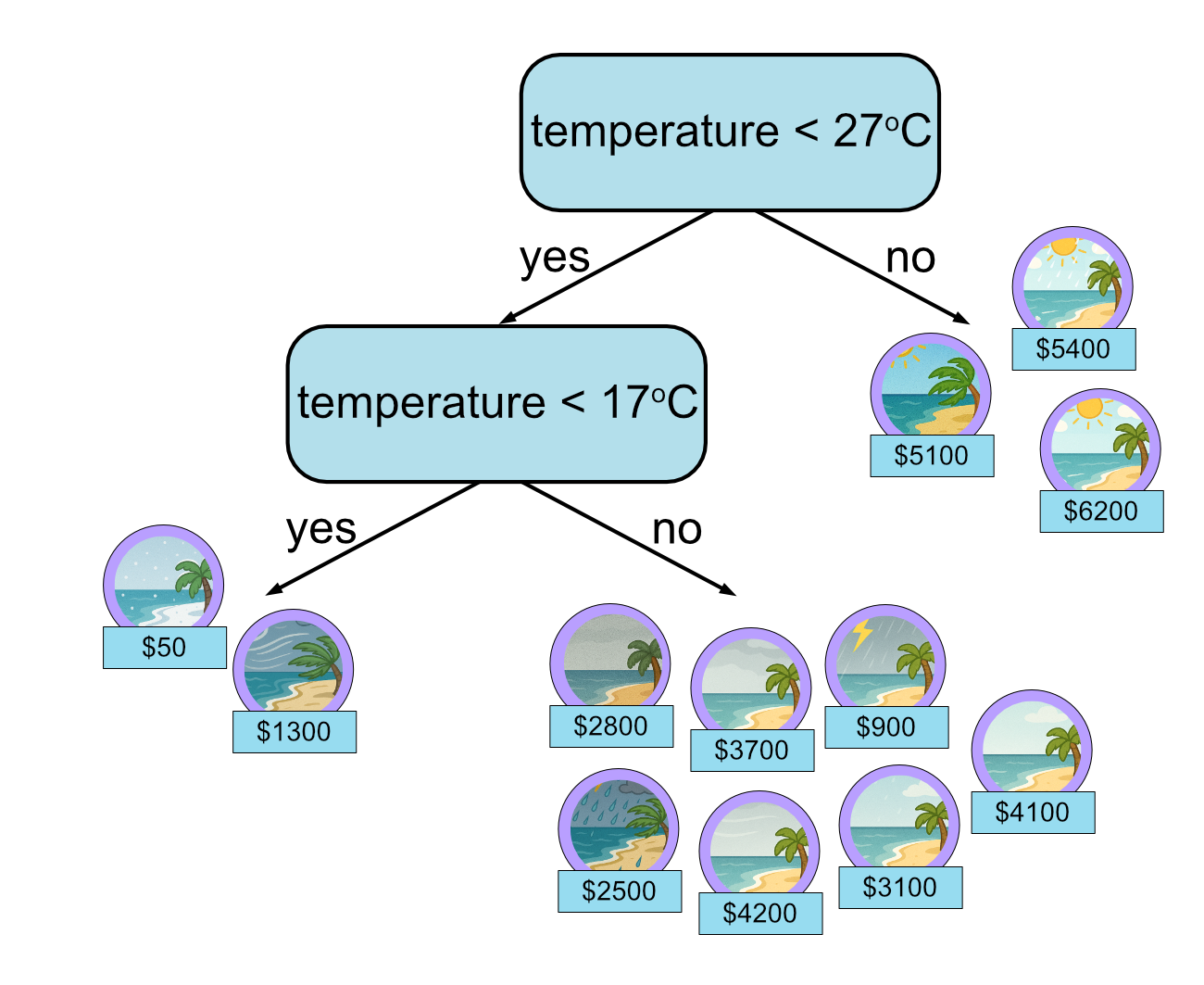
Second decision.
Third decision.
Let’s stop here.
In the slide ‘Node Impurity and Tree Height’, we discussed limiting the size of a tree by setting a maximum height. Another way we can limit a tree is set a minimum number of samples a node has to have for us to make a split. In this case we can say that there must be at least 5 samples for us to continue splitting. Once the node has less than 5 samples, we stop. As you can see, all of our leaf nodes correspond to less than 5 training samples.
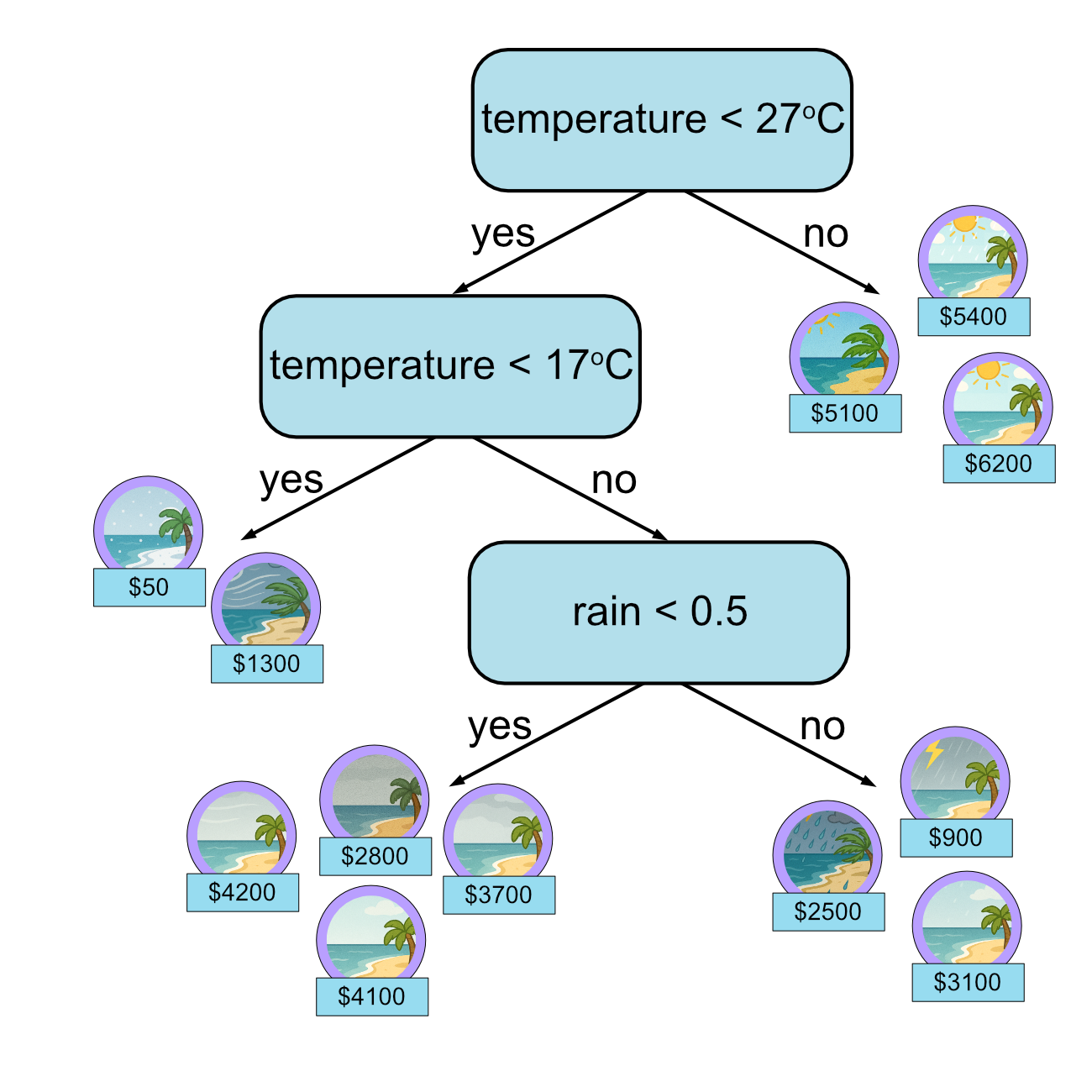
In a regression tree, once we have finished making all the decisions we take the average value of the samples in each leaf node. Here is our final regression tree: