4.2. Distance and Similarity#
Consider the following dataset which contains the age and height data of 3 people.
Name |
Age |
Height |
|---|---|---|
Alex |
5 |
100 |
Bailey |
30 |
190 |
Cameron |
40 |
150 |
Dani |
60 |
160 |
Here is a visualisation of this data:
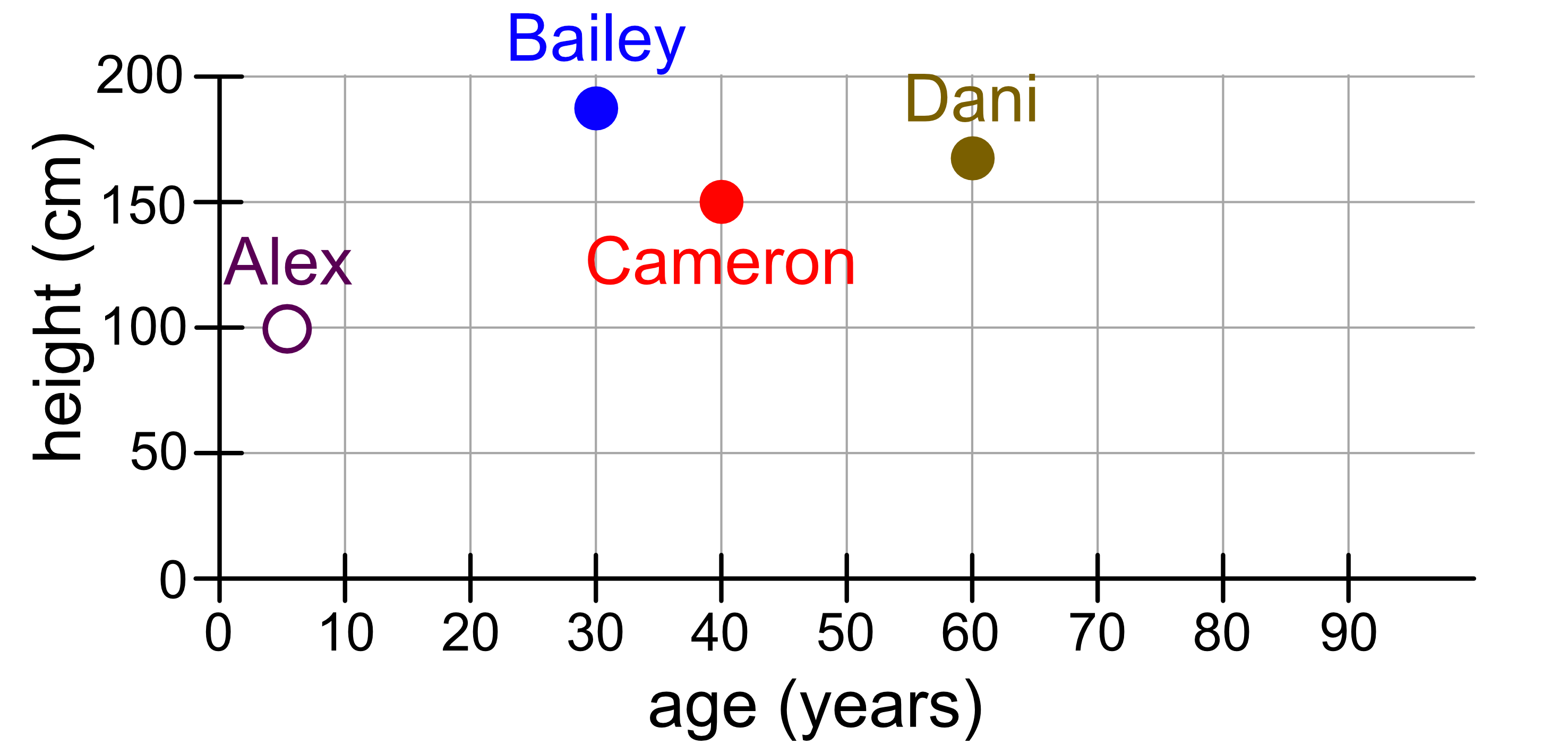
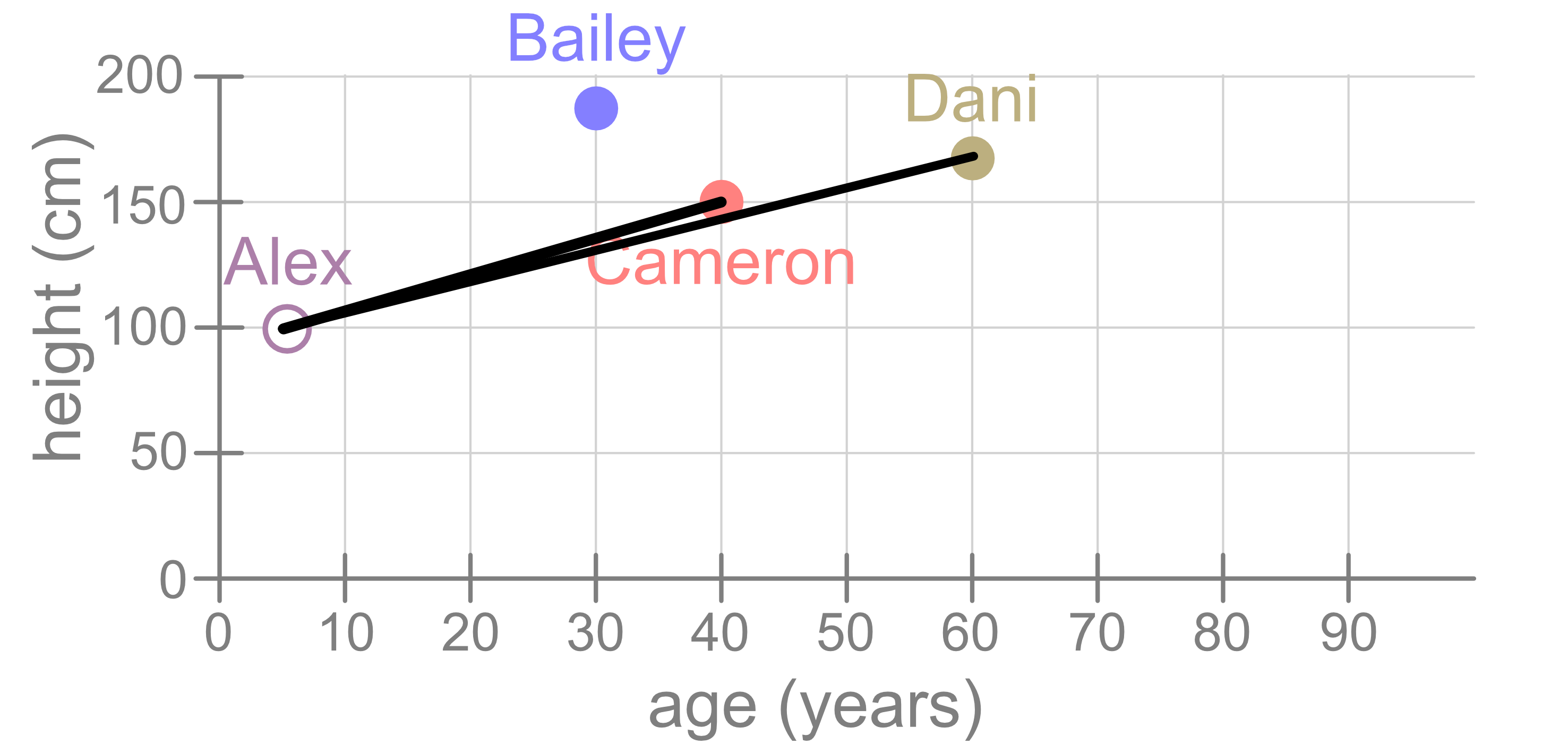
You should be able to see why it makes intuitive sense that the distance between points can be used as a metric to measure similarity. For example, you can see visually that the distance between Alex and Dani is much larger than the distance between Alex and Cameron. If you look at the height and ages of these three people, Alex is closer in both age and height than they are to Dani.
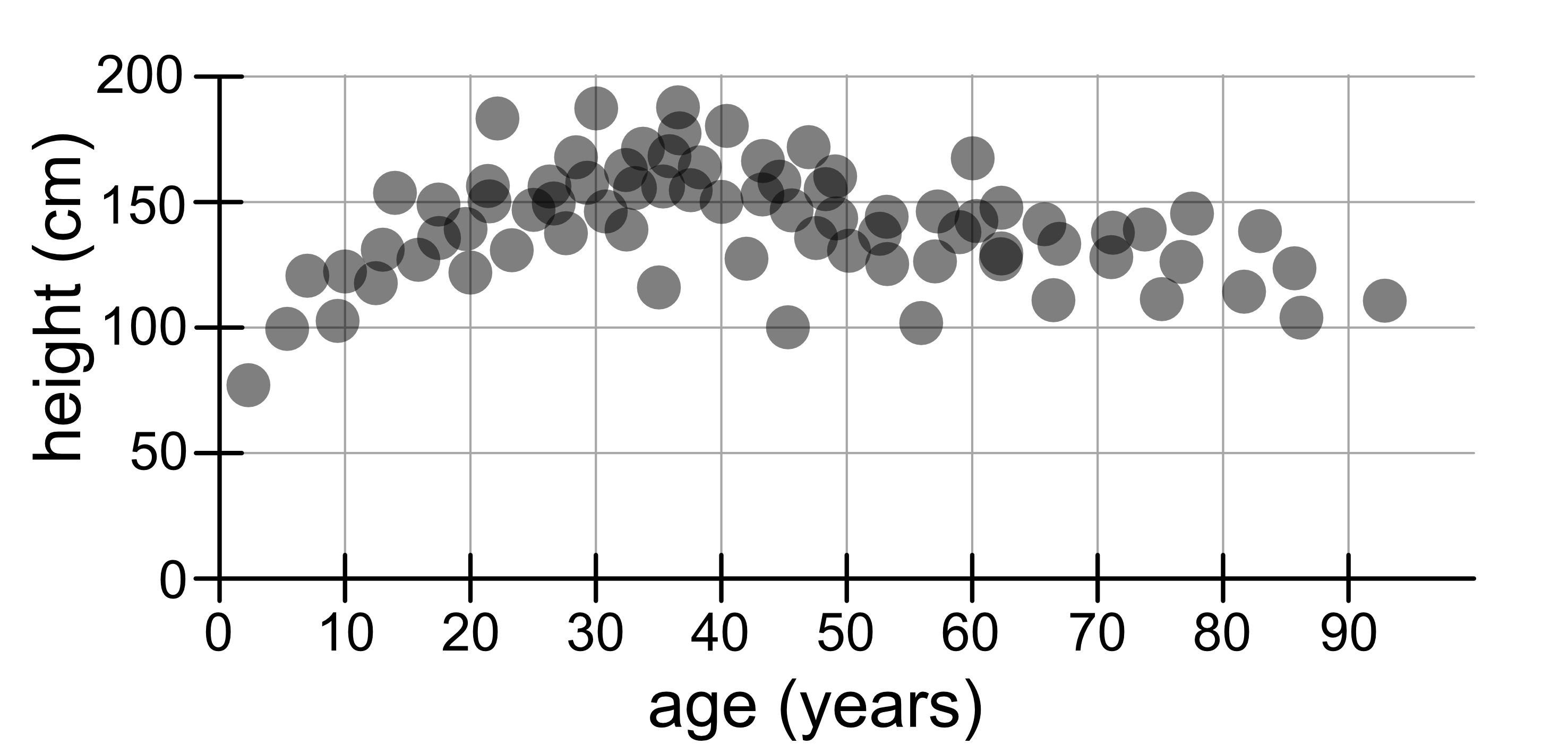
In general, if you consider a larger dataset, the points that are close together are similar in both age and height. The closer the points are, the more similar they are. If two people are similar in one variable but quite different in another variable (e.g. similar height but different ages), they won’t necessarily be close together.