4.4. KNN Regression 1D#
K-nearest neighbours (KNN) regression is a commonly used machine learning algorithm for regression (predicting numbers). The way it works is that you make a prediction based on other similar samples.
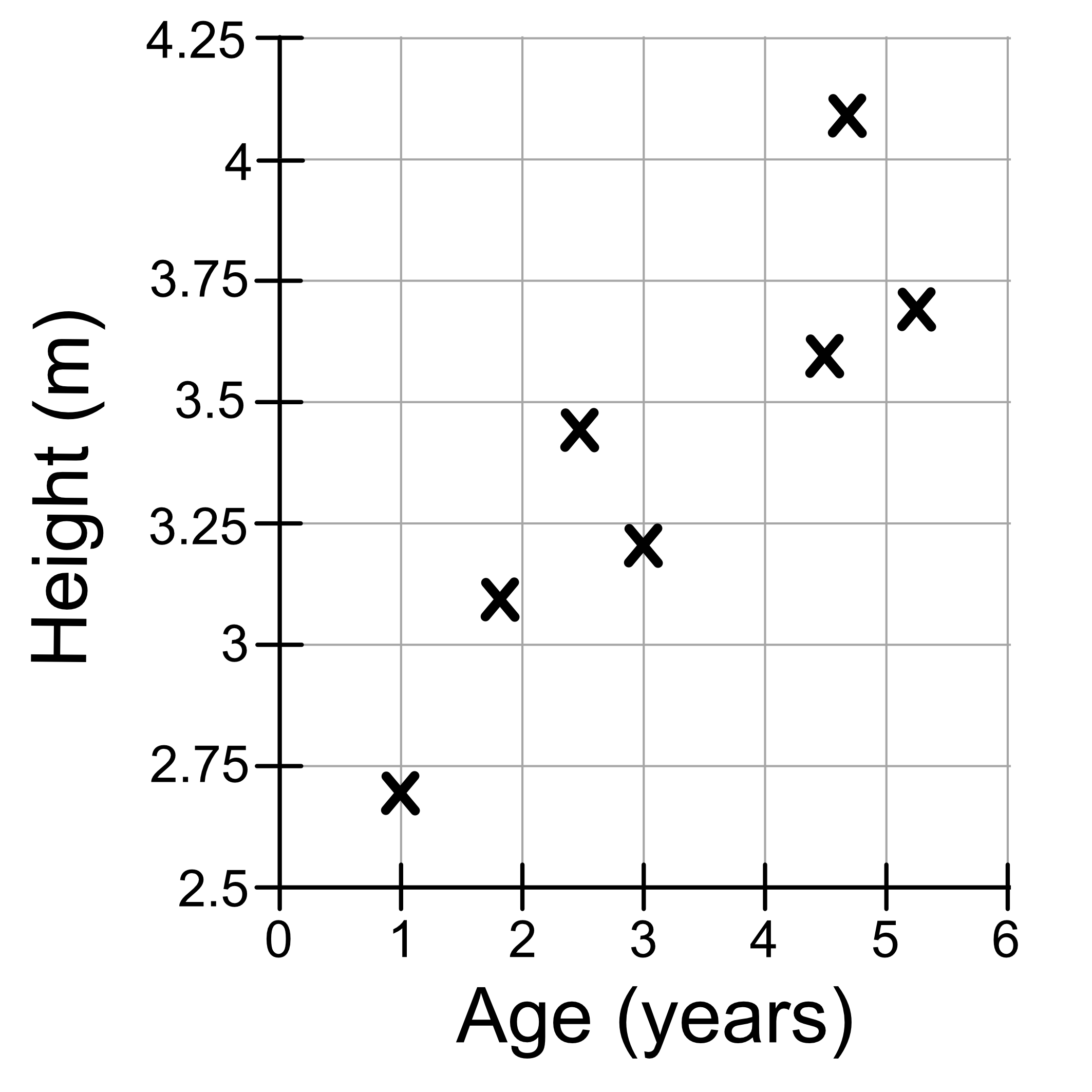
Consider the following dataset containing giraffe age and heights:
Age (years) |
Height (cm) |
|---|---|
1.0 |
2.7 |
1.7 |
3.1 |
3.0 |
3.2 |
2.4 |
3.4 |
4.7 |
4.1 |
5.2 |
3.7 |
4.5 |
3.6 |

It we were to plot out this data it would look like this.
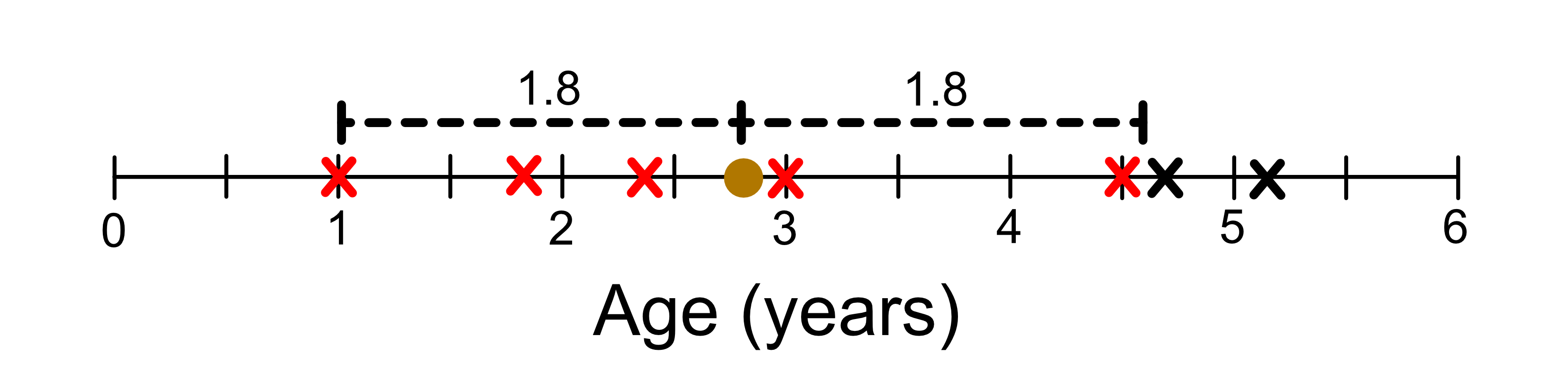
Now the way a KNN regression model makes a prediction is that it looks for the closest sample in the training data. For example, let’s say we wanted to predict the height of a giraffe who was 2.8 years old. The information we have on our unknown giraffe is just it’s age. If we were to plot just the age information it would look like this:

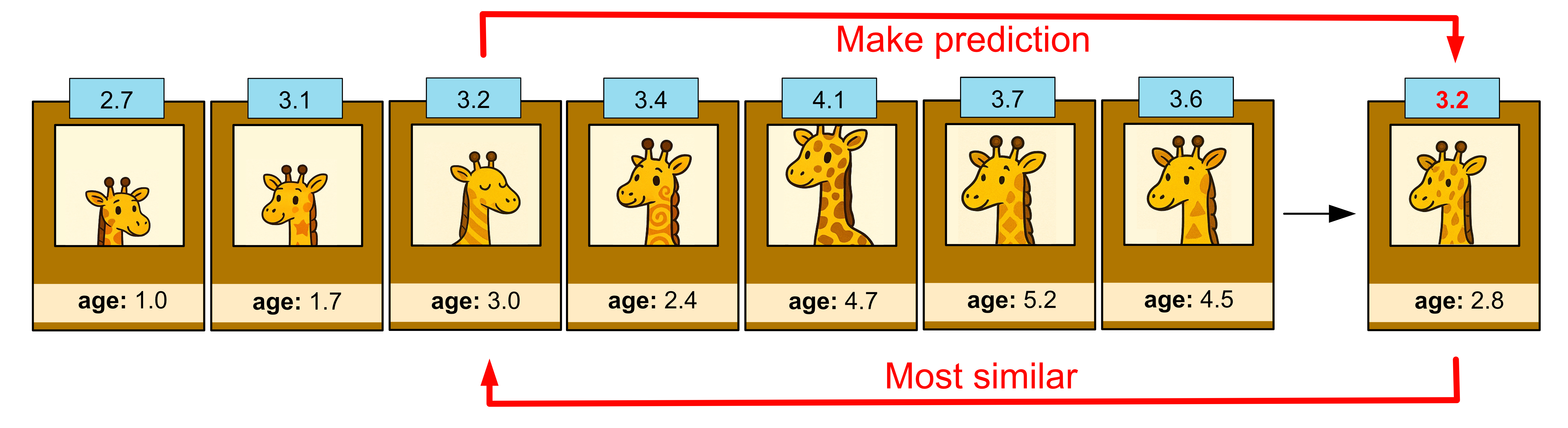
Using distance as a measure for similarity we can see that the most similar giraffe is 3 years old.
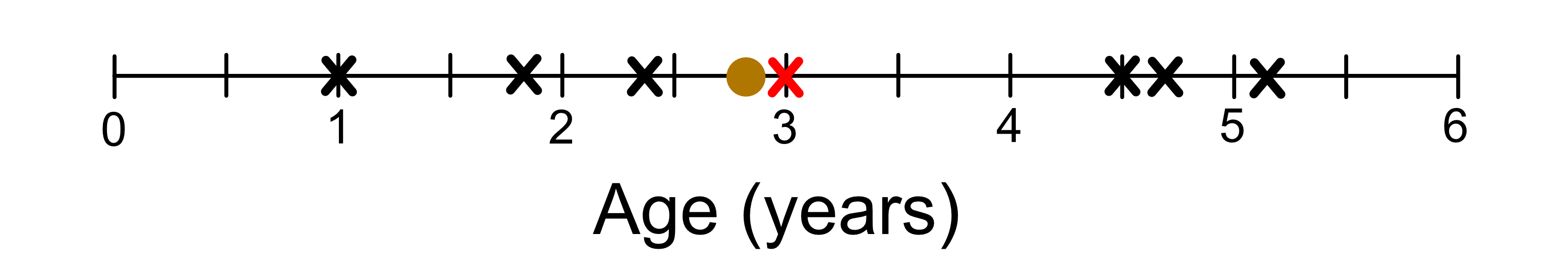
This giraffe happens to have a height of 3.2m. Thus, we predict that our giraffe is 3.2m tall.
4.4.1. The ‘k’ in K-Nearest Neighbours#
In KNN, ‘k’ refers to the number of neighbours used to make an estimate. In the example above we made on estimate using only one ‘neighbour’, i.e. the one closest sample in our training set.
If we set k = 2, this means we use the two closest ‘neighbours’ in our dataset and we take their average height.
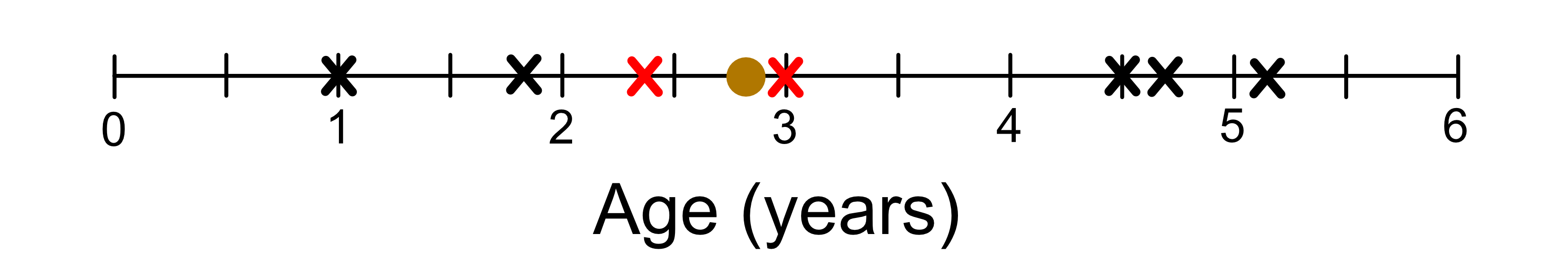
The two giraffes that are most similar in age are 2.4 and 3.0 years old. They have heights 3.2 and 3.4. The average of these values is 3.3, so we predict our giraffe is 3.3m tall.
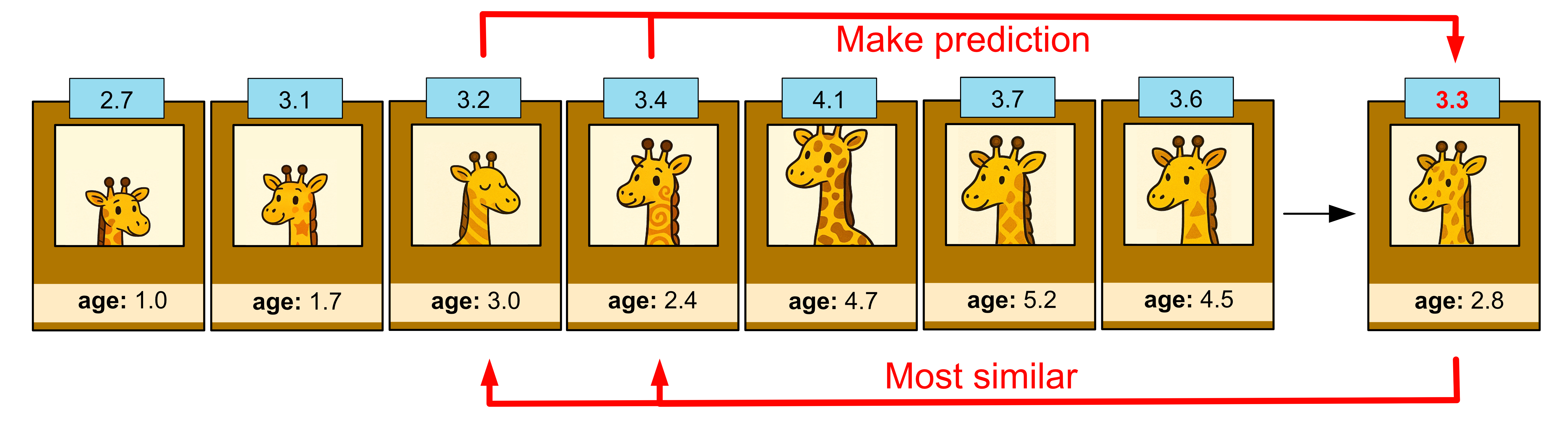
If we set k = 5, this means we take the five closest ‘neighbours’ in our dataset and we take the average height.
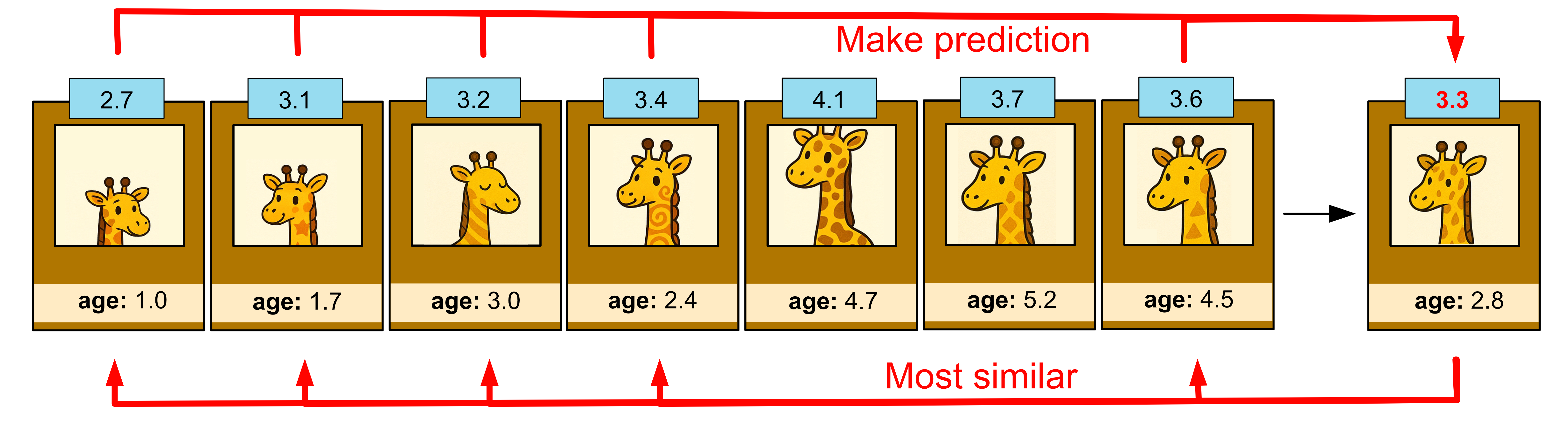
Depending on the value of k you choose, you will get a slightly different model.