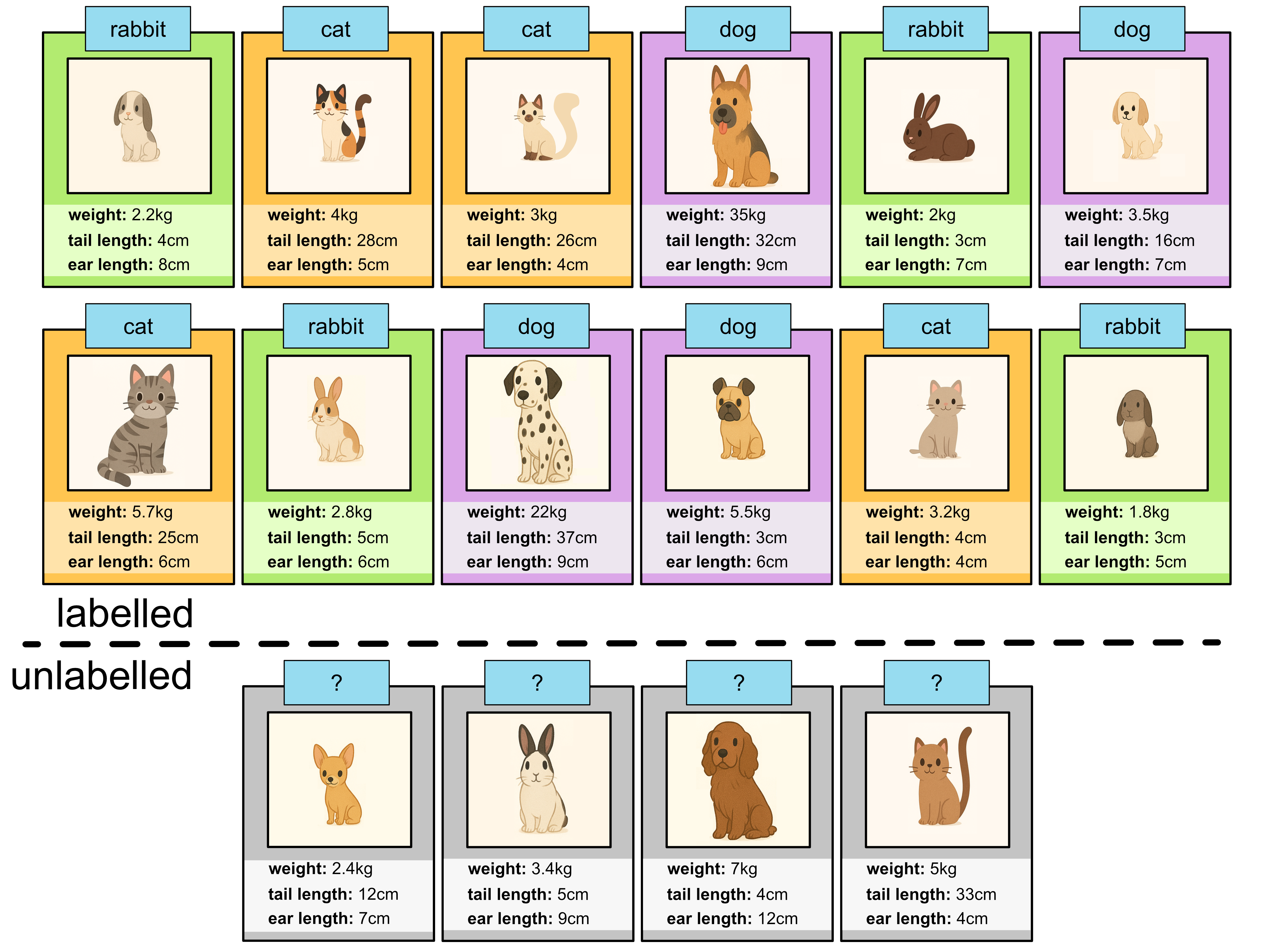
3.5. A Semi-Supervised Model#
Thus far we have only been looking at machine learning models applying supervised learning. Recall that supervised learning means that our data is labelled.
Sometimes it can be hard, cumbersome or expensive to obtain labelled data. E.g. for our cat/dog/rabbit example it would require someone to look at lots of samples and identify whether each animal is a cat, dog or rabbit. But let’s assume we had more samples that were unlabelled. It would be beneficial if we were able to incorporate these into our model, since the more information we have, the better we expect our model to be. But the problem is that these samples don’t have labels. Now we could label these ourselves, but if we had lots and lots of samples, this would be extremely time consuming, so we’ll look at how we can automatically assign labels to our data.
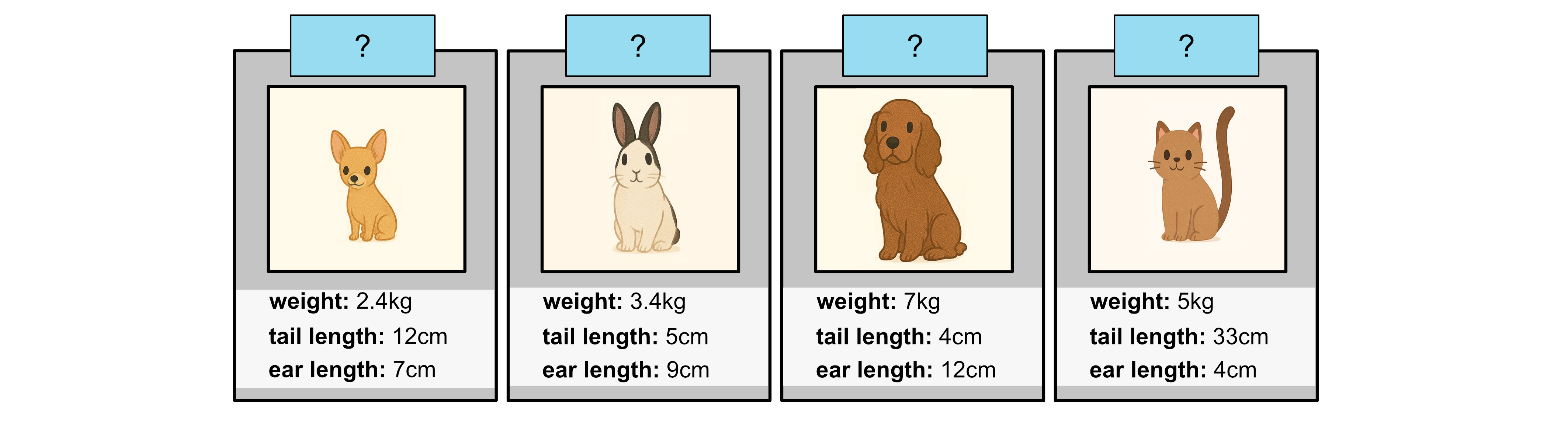
What we’ll do is we’ll classify each of these samples using our existing classification tree.
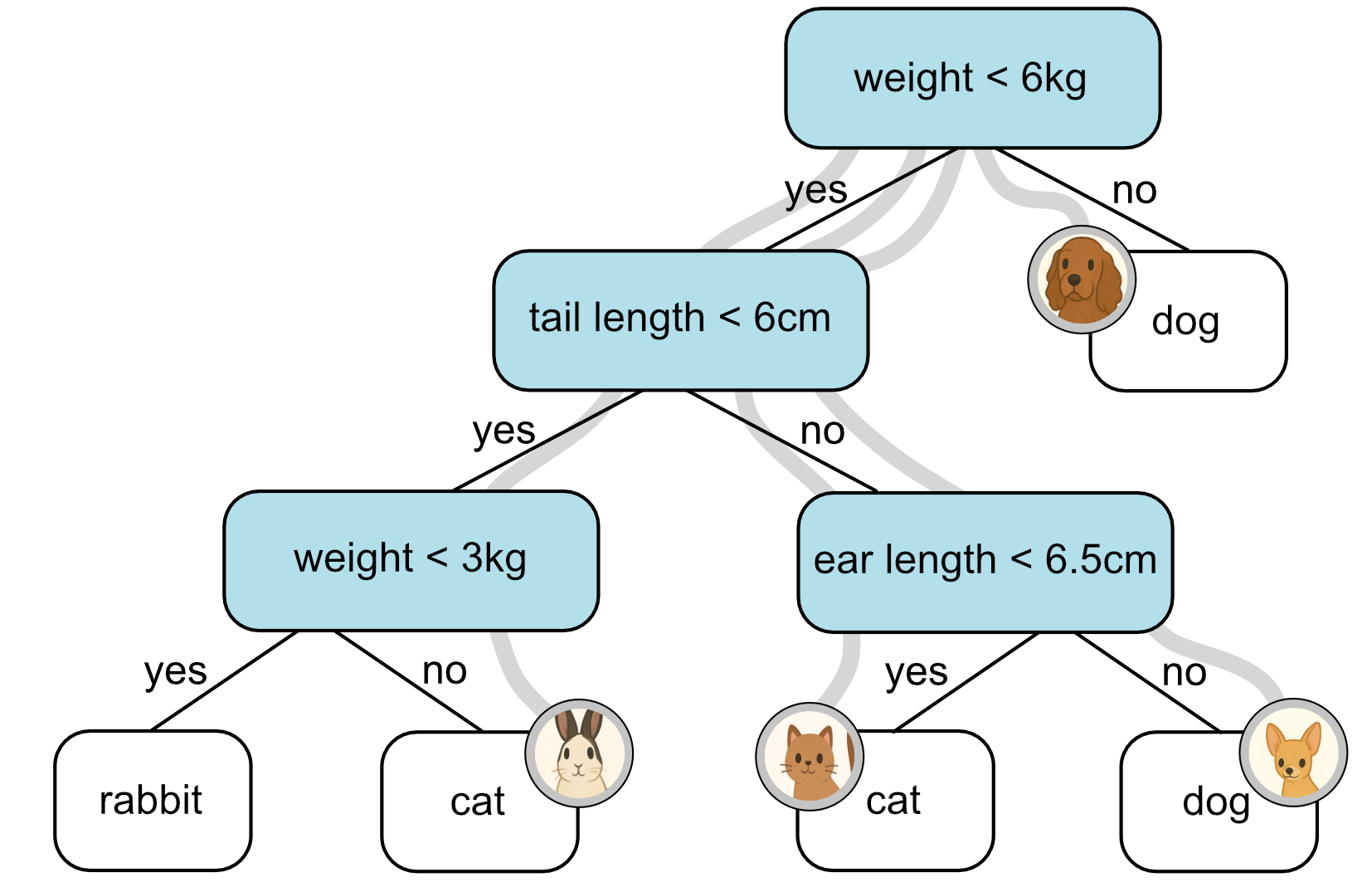
Here are our classifications.
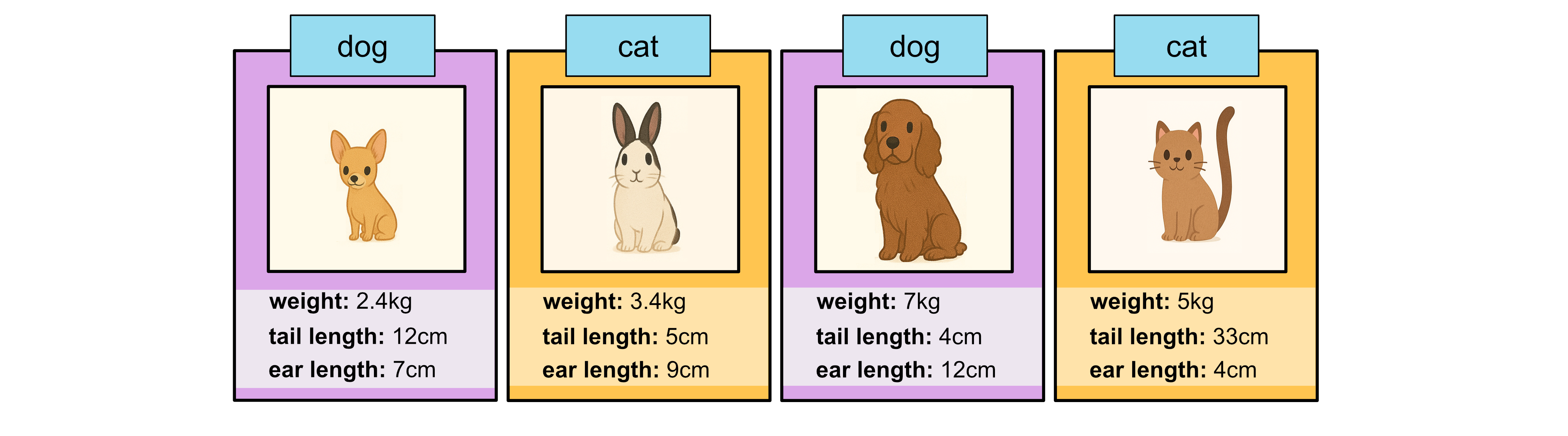
You’ll see that the model won’t necessarily get all the labels right, but for the most part it will do reasonably well. We can now add these samples into our training data.
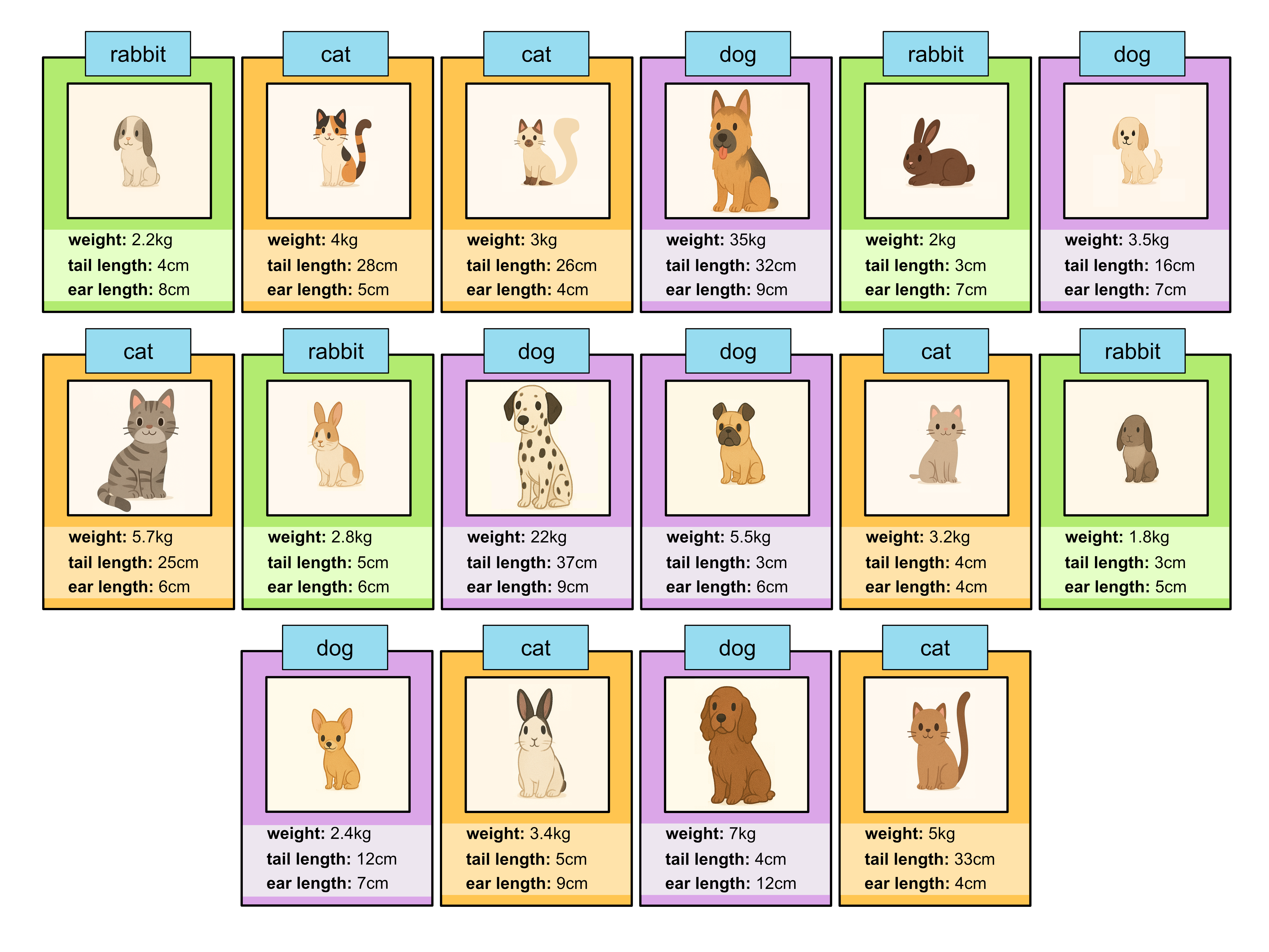
Using this larger training set we can rebuild our classification tree, and hopefully improve the model’s performance.
This technique is a form of semi-supervised learning because the training set is comprised of both labelled and originally unlabelled data. This is what our original dataset would have looked like.