3.6. Random Forests#
When we previously looked at semi-supervised learning, we saw that we had incorrectly labelled a rabbit as a cat.
This means that when we added this data to our training set, we provided our model with incorrect data. Ideally, we want to provide our model with correct data. One way in which we can do this is to use a method called a random forest.

The idea behind a random forest is to construct an ensemble (a group) of different classification trees and then classify based on the majority ‘vote’ of all the trees.
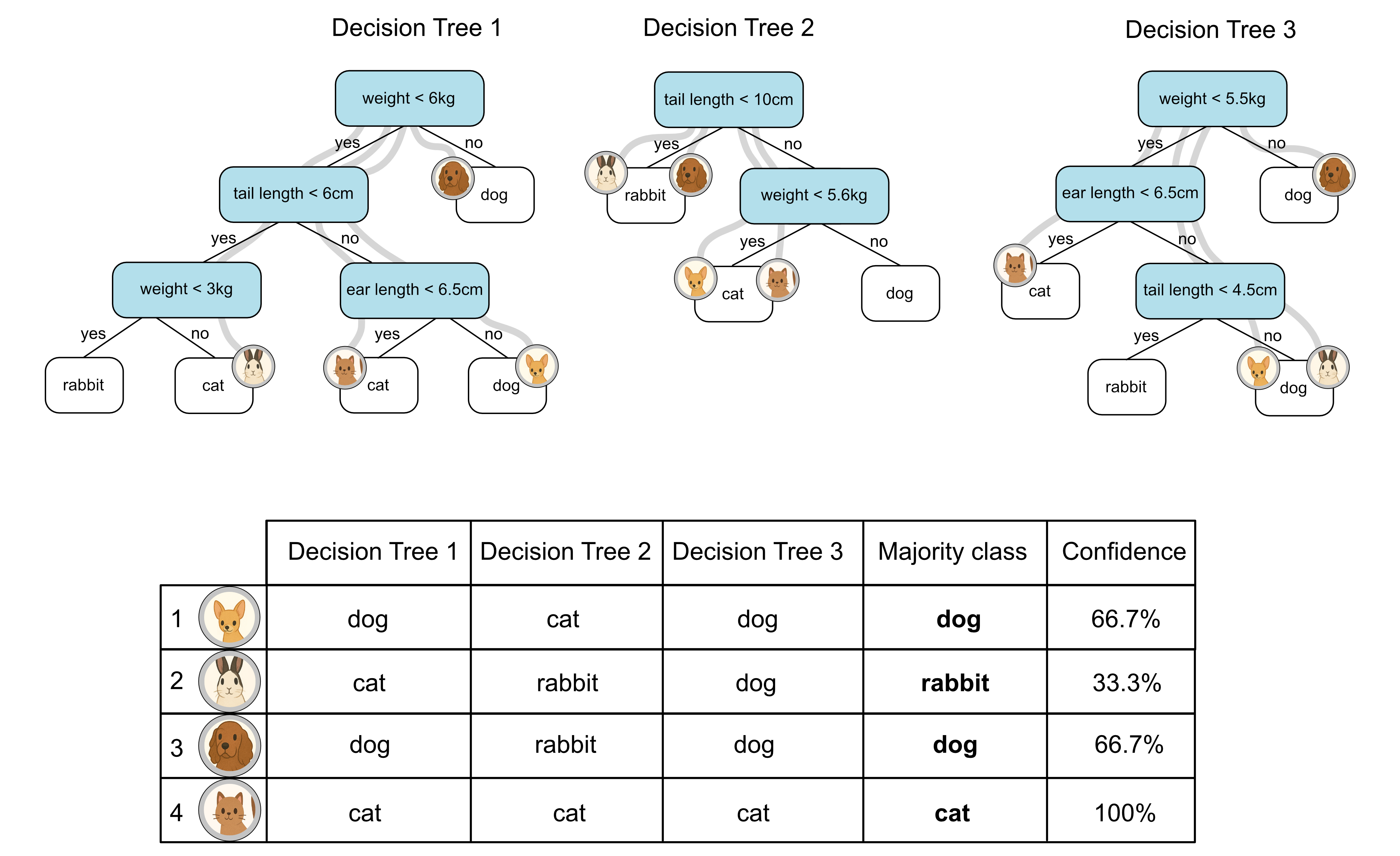
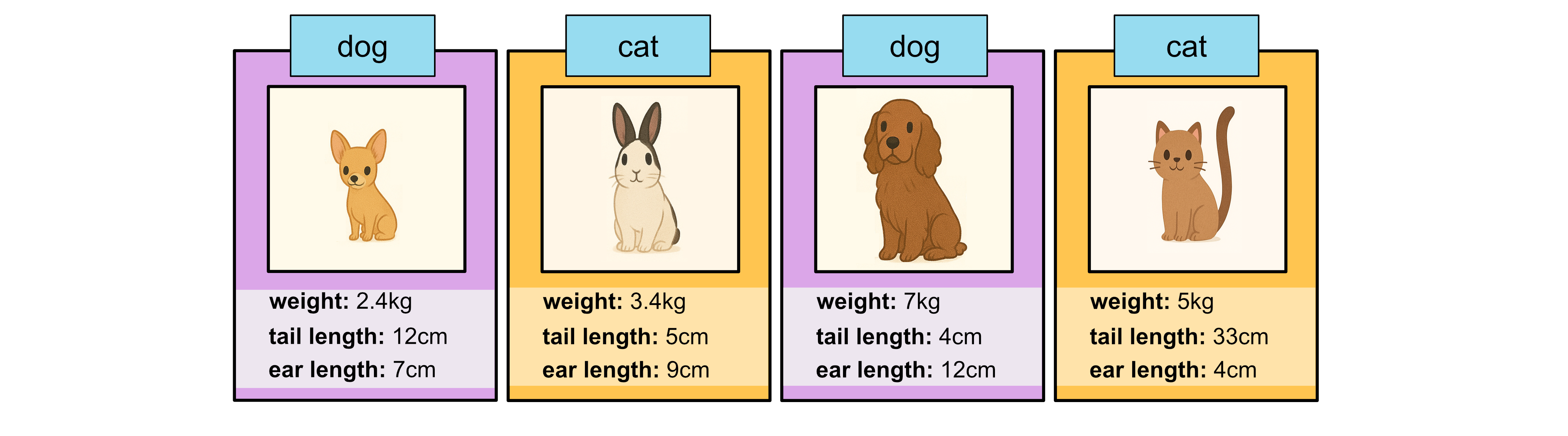
To try to increase the accuracy of the samples we add to our training data, we’ll only add the samples we’re confident in. We calculate confidence based on how the trees ‘voted’. For example, all 3 tree voted sample 4 as a cat, so we are 100% confident it is a cat. Only 2 of the 3 trees voted sample 1 as a dog, so we are 2/3 = 66.7% confident the first sample is a dog. We might then say we will only add samples to our training data if we are 65% confident that they have been correctly labelled. This means we would only add samples 1, 3 and 4 to our training data.
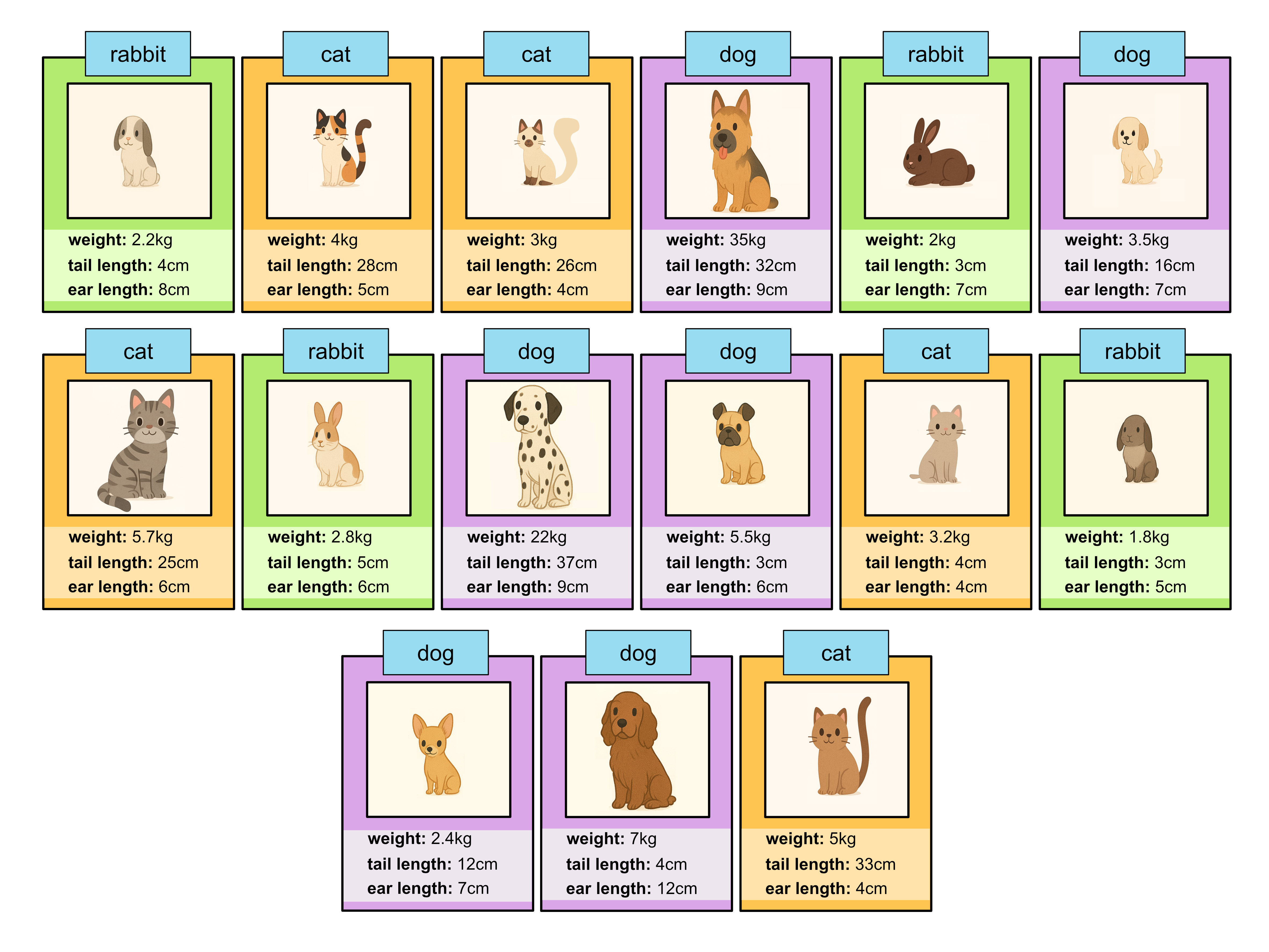
In a random forest we tend to want all of the classification trees to ‘think’ quite differently. If all the trees are very similar, you might as well just use one tree. In order to make the trees different, we can intentionally limit the variables that it can make a decision on. E.g. in this case, we might force the first tree to make it’s first decision based on weight and then it’s second decision on tail length. Then we might force the second tree to make it’s first decision based on ear length etc. This forces the trees to be very different.