5.8. Problem and Model Analysis#
Looking at the results below you can see that our trained neural network performs much better on our test samples than our untrained neural network. It doesn’t do well on the first sample, but does quite well on the next two.
Predictions From The Untrained Neural Network
Sample |
Predicted |
Actual |
Error (Predicted - Actual) |
|---|---|---|---|
(150, 25, 150) |
(107, 32) |
(300, 71) |
(-193, -39) |
(50, 60, 180) |
(124.3, 38.8) |
(235, 57) |
(-110.7, -18.2) |
(250, 200, 170) |
(170, 50) |
(23, 89) |
(147, -39) |
Predictions From The Trained Neural Network
Sample |
Predicted |
Actual |
Error (Predicted - Actual) |
|---|---|---|---|
(150, 25, 150) |
(107, 32) |
(300, 71) |
(-191.4, -12.4) |
(50, 60, 180) |
(124.3, 38.8) |
(235, 57) |
(-13.6, 14.8) |
(250, 200, 170) |
(170, 50) |
(23, 89) |
(0.9, -40.6) |
Still, our trained neural network isn’t performing incredibly well, so why is that? Some possible reasons are given below.
5.8.1. 1. We need to train for longer#
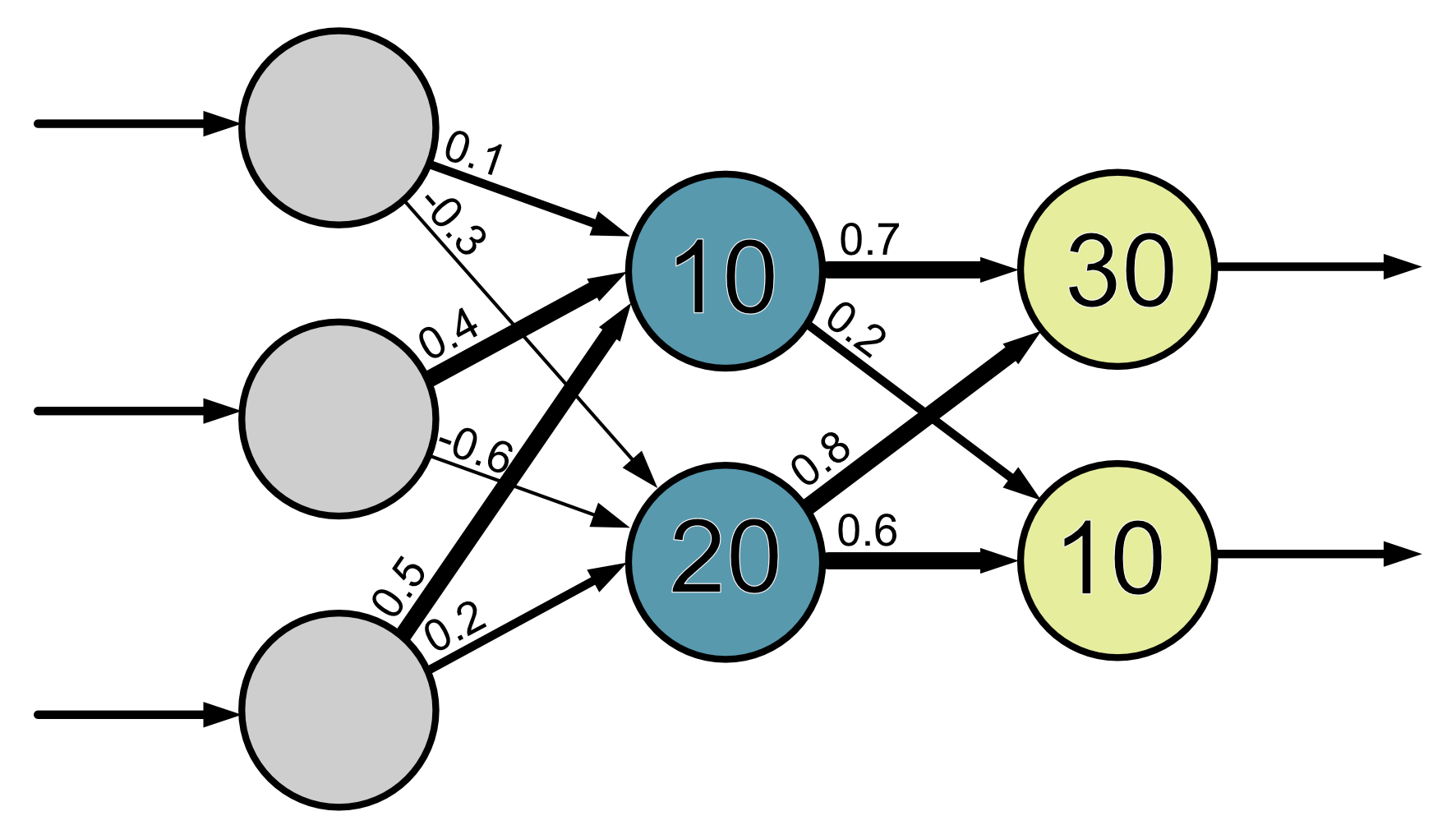
Neural networks are quite complicated. The models themselves have lots of parameters that need to be fit, i.e. we need to work out the best value for every single weight and bias. If we think about our simple neural network with just one hidden layer containing only two neurons:
5.8.2. 2. We need more training data#
We only trained our neural network using 5000 training samples. Typically the more training data the better, and since neural networks are very complicated (in that they have a lot of parameters to fit), they generally need a lot of data to learn from. Typically a rule of thumb is that you want 10x more training samples than their are parameters in your network. Large neural network require millions of training samples.
The amount of training data you need also depends on the difficulty of the problem you’re trying to solve. The harder the problem, the more training data you need. Previously we looked at building a neural network the predicted \(y\) where \(y = x_1 + x_2\). For that we only used 100 training samples and a smaller neural network because that was a much easier problem to solve than predicting hue and saturation from RGB values.
5.8.3. 3. We need a larger neural network#
The larger the neural network, the more complex the relationships the neural network can ‘learn’. The way you can think about it is that the larger a neural network is the bigger its ‘brain’ capacity. One of the problems with having a large network is that they take longer to train, and you need more data to train them, but it can be done. Often neural networks are trained for a long time in advanced and then the values of the weights and biases are saved so that the trained network can be used without need the network to be trained again each time. For example, when we us tools such as ChatGPT, the neural network that sits behind it has been pre-trained on lots of data.
5.8.4. 4. The problem we are solving is hard#
The calculation of hue and saturation from RGB values is actually quite complicated. For example, in the gif below you can see that when we increase in G, the saturation can either increase or decrease, there isn’t a clear relationship between these variables. Similarly, you’ll notice that the value of the hue can jump suddenly.

Here’s another example:
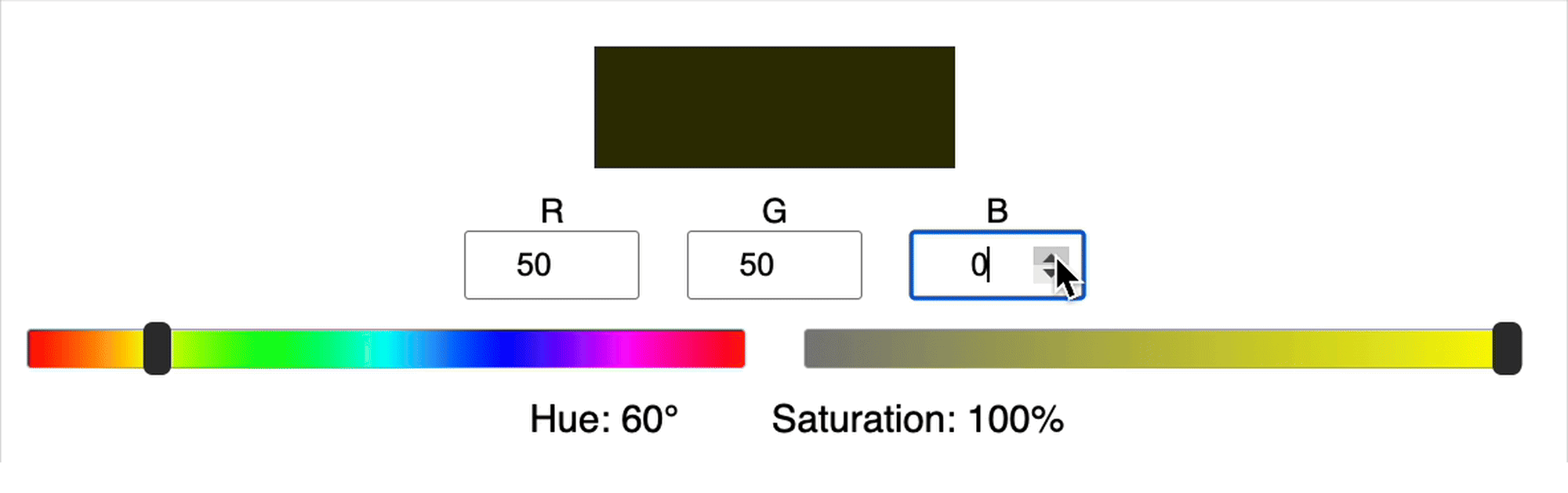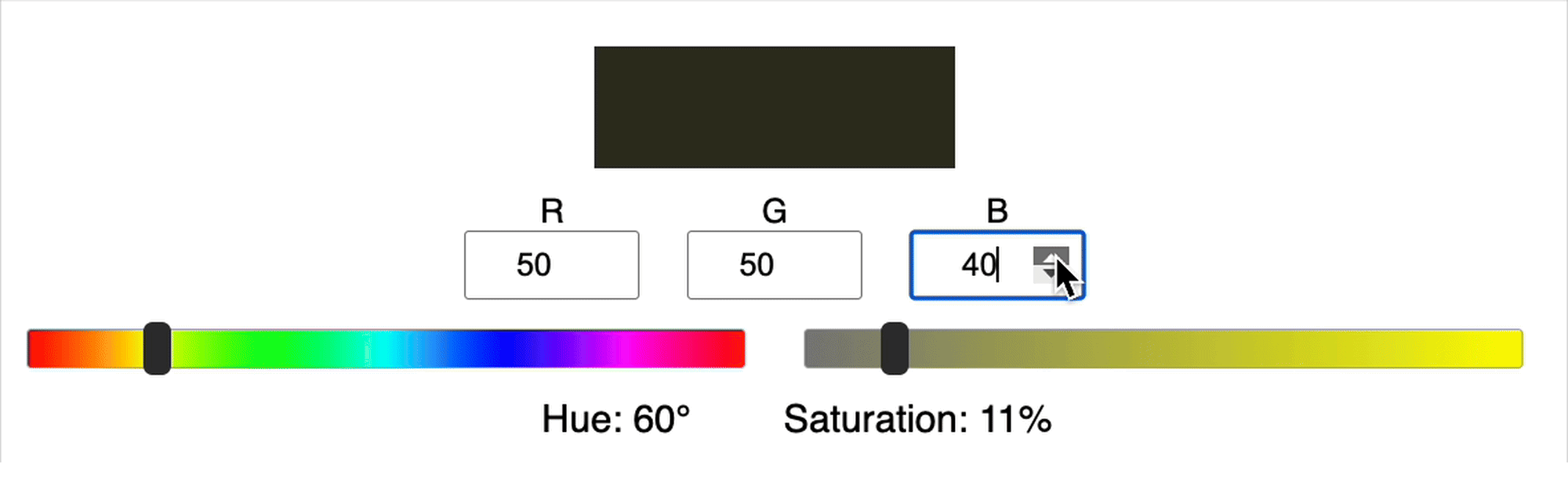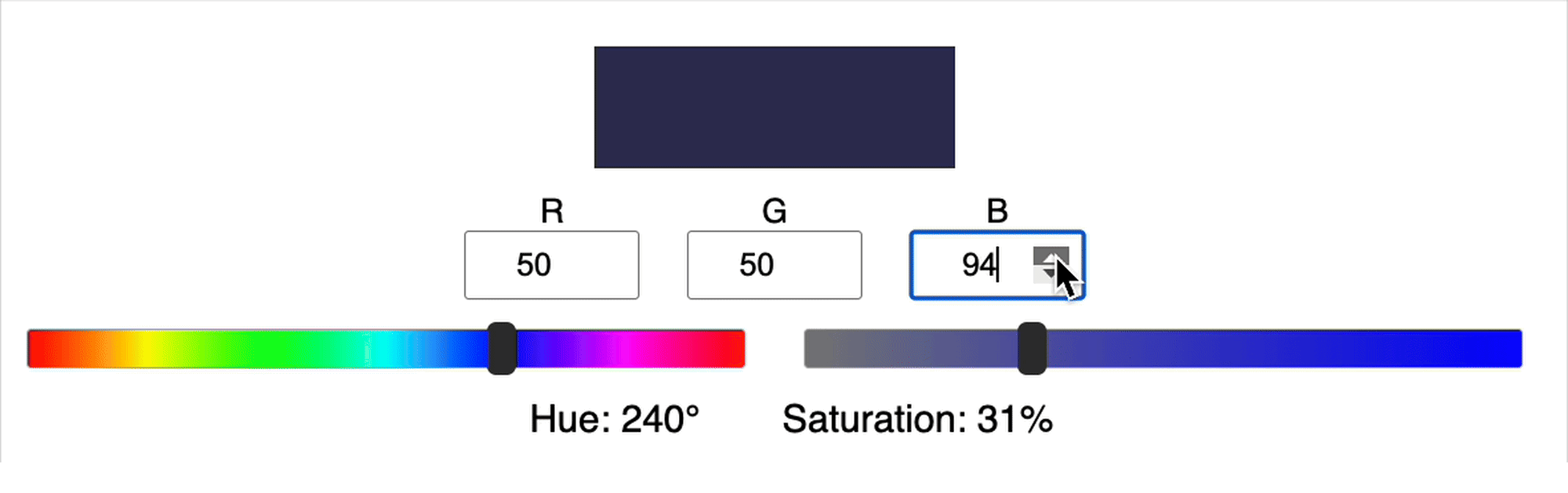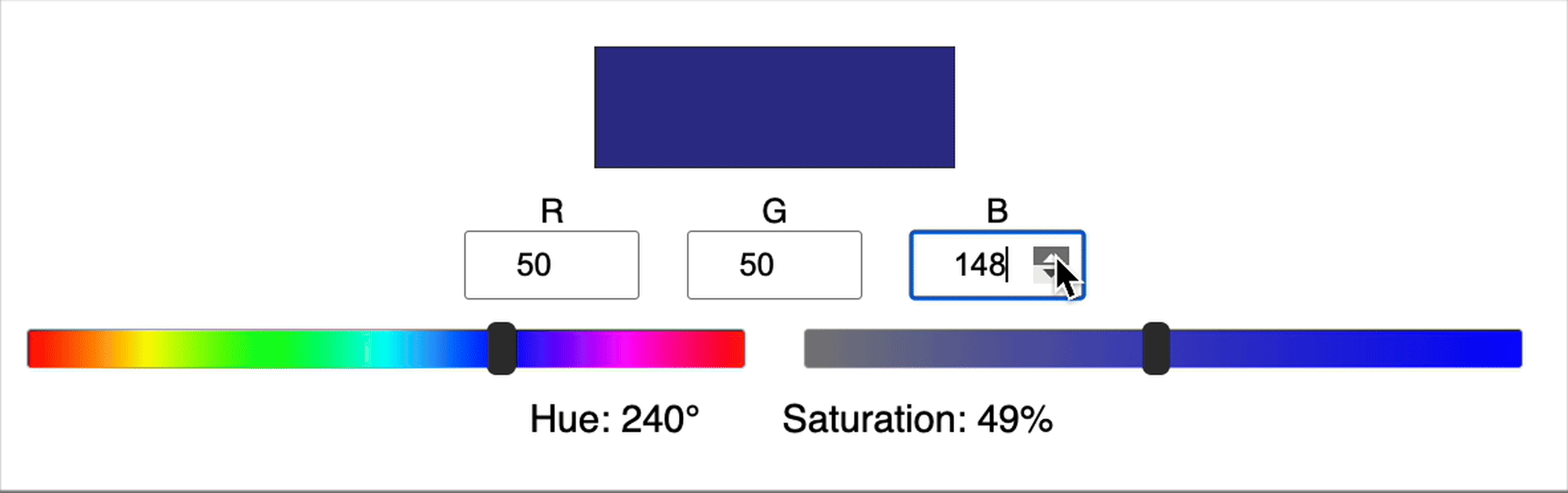
Since the relationship between the input (RGB) and output (hue and saturation) is complicated, typically it means we need a larger network and/or more training data and/or more training time.
5.8.5. 5. Selecting appropriate hyperparameters#
Other things to be mindful of when training the network is that we have
selected appropriate hyperparameters. These are the arguments used when
building the neural network model, e.g. max_iter and learning_rate, and
they control how the neural network learns. The process of experimenting to
select good hyperparameters is called hyperparameter tuning.