6.1. Reinforcement Learning#
One type of machine learning that we haven’t looked at at yet is called reinforcement learning. This is essentially where the computer learns via trial and error.
You can think of reinforcement learning like training a dog to sit on command. At any moment, the dog has a choice of actions it can take, like sitting, jumping, barking, or doing nothing.
When you say “sit,” and the dog chooses to sit, you give it a treat as a reward. If it does something else, like barking or ignoring you, it gets nothing.
Over time, the dog starts to notice a pattern: sitting when you say “sit” earns a treat. Since the dog wants as many treats as possible, it gradually learns that the best way to get rewards is to sit at the right time.
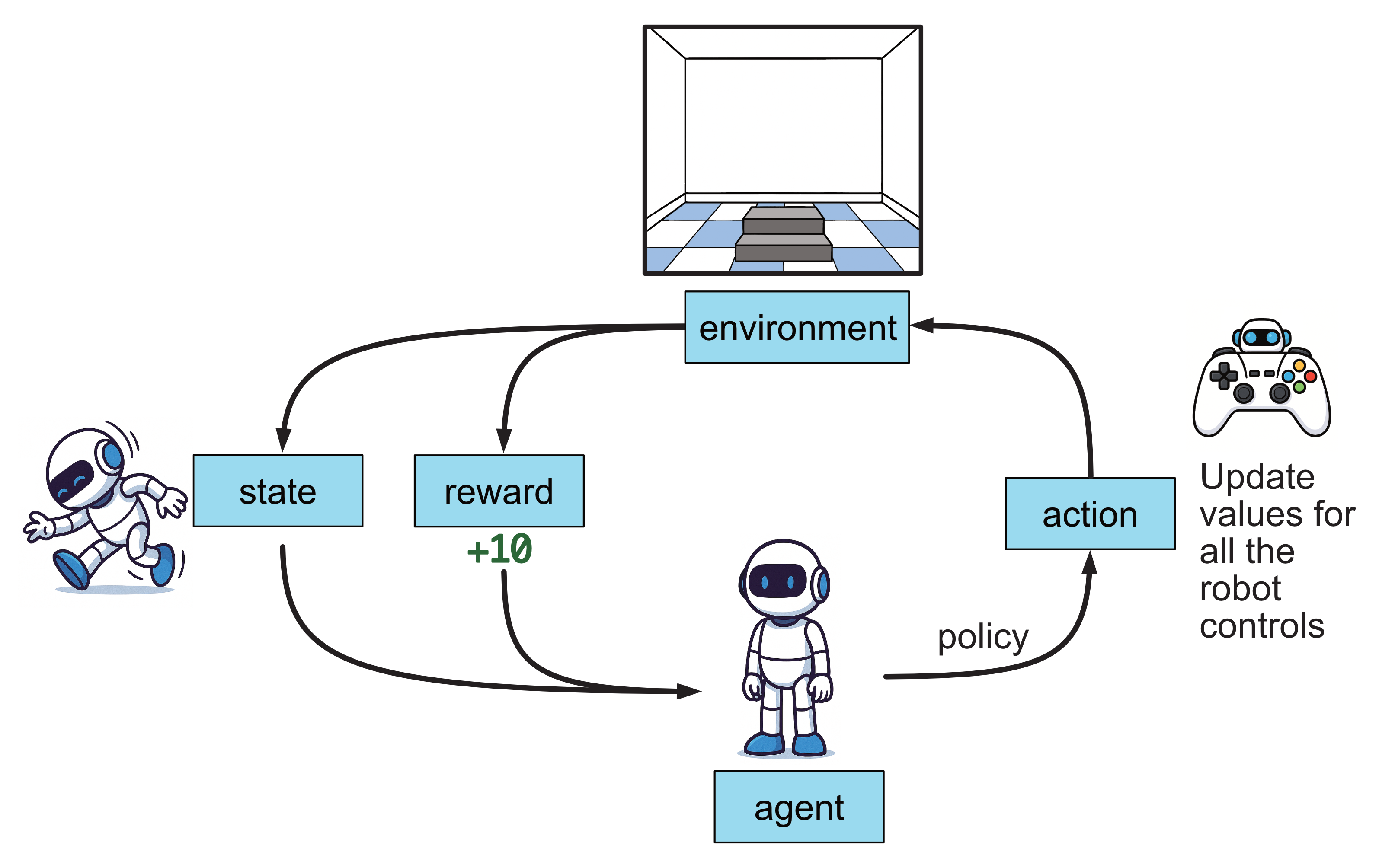
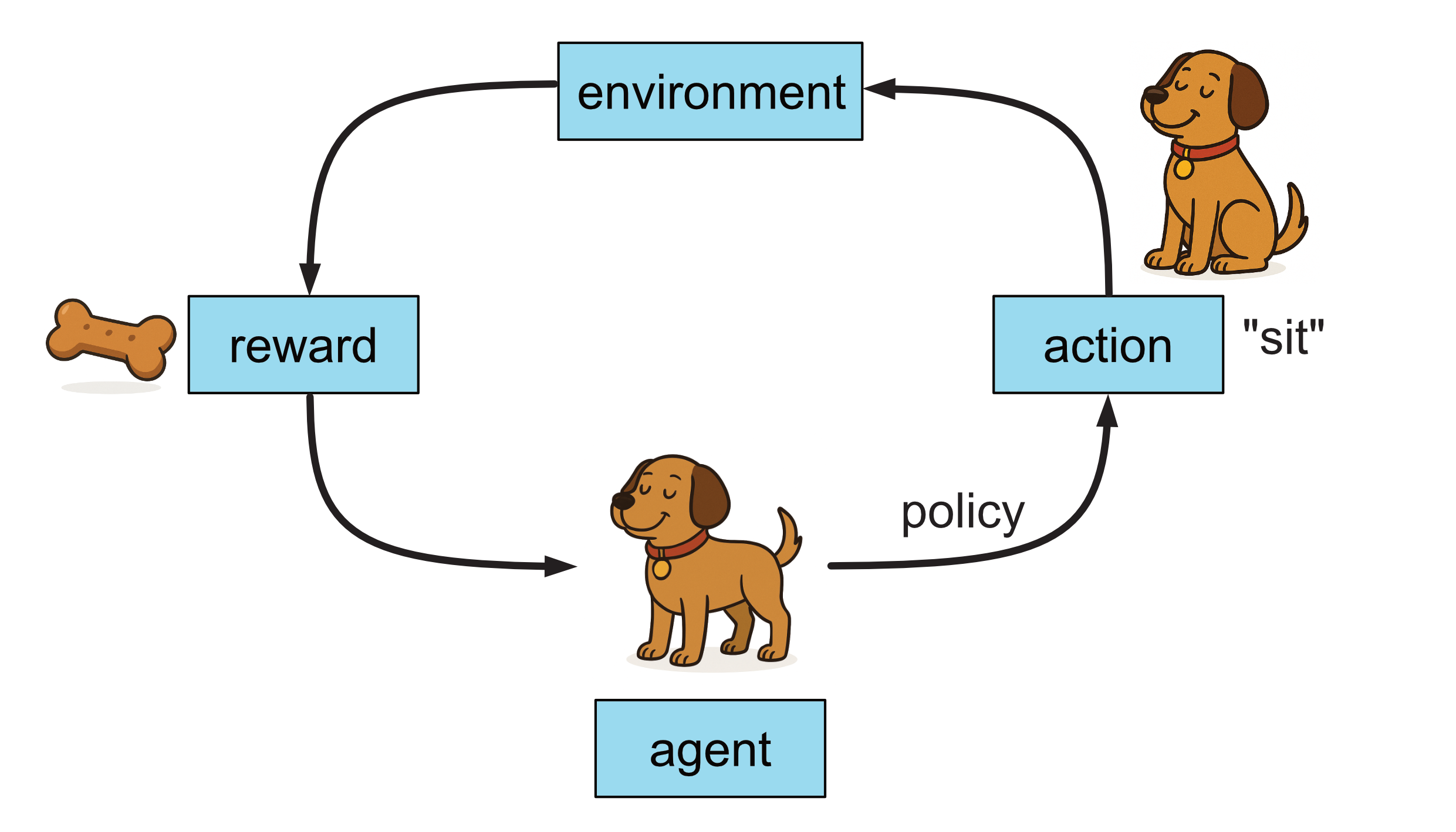
This is the core idea behind reinforcement learning: the agent i.e. the learner (in this case, the dog) tries different actions, receives feedback (rewards or no rewards), and gradually figures out the best strategy to get the most rewards in the future. What the agent learns is a policy, which is essentially a set of instructions that tell it how to behave based on it’s environment to maximise it’s reward. In our example here, the dog’s policy will be something along the lines of when they say ‘sit’, I sit.
6.1.1. Example - Brick Breaker#
This approach can be applied to lots of different context. For example, let’s think of the video game brick breaker.
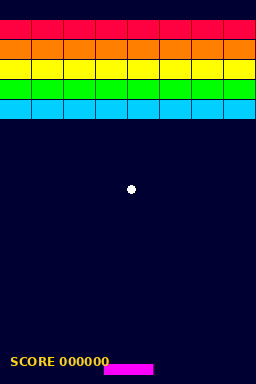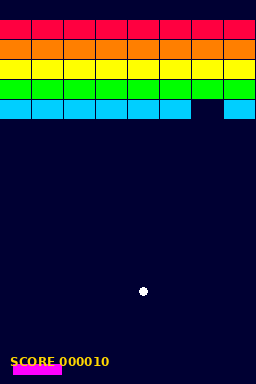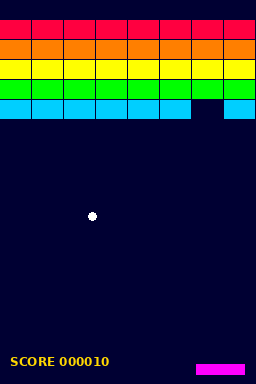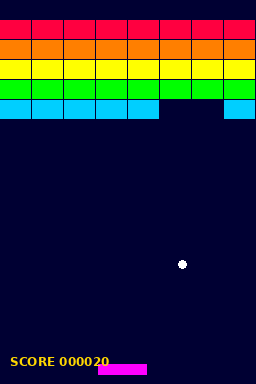
The objective of the game is to use the left and right arrow keys to move the platform and keep the ball in play. Each time the ball hits a brick, the brick breaks and you score points.
If you were to build an agent using reinforcement agent to play this game, this is what the processes would look like.
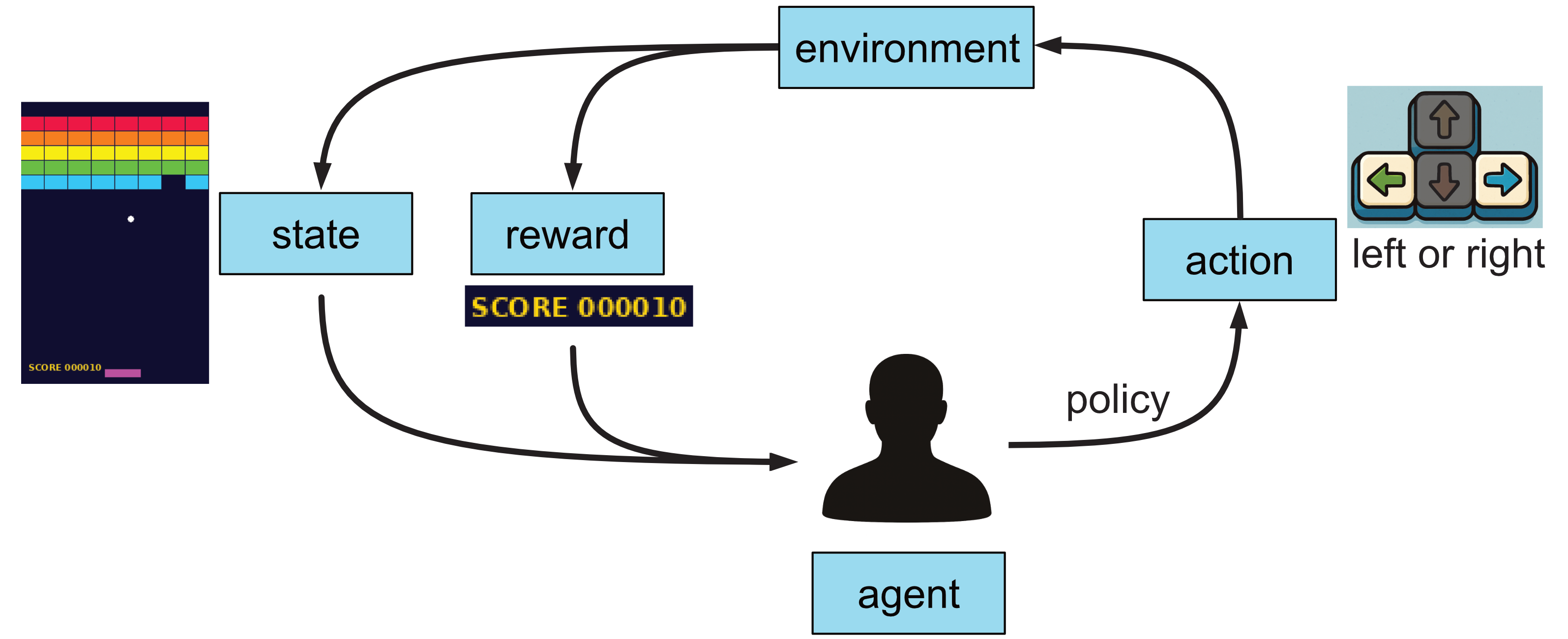
In addition to receiving a reward, we also have access to the game state, which represents the current status of the game. The agent learns a policy that guides its decision to move the platform left or right, depending on this state. When the agent starts learning, it’s decision to move left or right will be quite random. As the agent plays the game more, it learns whether to move left or right based on the game state to maximise its score, which means it gets better at playing the game.
6.1.2. Example - Walking Robot#
Another example might be to in teaching a robot to walk. The agent receives points for being able to stand upright and move forward. Over time, through trial and error the agent learns a policy to maximise the points it gets, and over time it is able to control the robot to enable it to walk.